Liked what you read? I am available for hire.
Author Archives: kevin
links for 2010-11-25
-
don't sign things you can't understand. but yeah, this guy is pretty evil
Liked what you read? I am available for hire.
links for 2010-11-22
links for 2010-11-21
-
Funny, I wanted to write a script that does this... nice
Liked what you read? I am available for hire.
links for 2010-11-15
-
"A human mind is a wandering mind, and a wandering mind is an unhappy mind. The ability to think about what is not happening is a cognitive achievement that comes at an emotional cost. "Mind-wandering appears ubiquitous across all activities. This study shows that our mental lives are pervaded, to a remarkable degree, by the non-present. Mind-wandering is an excellent predictor of people's happiness. In fact, how often our minds leave the present and where they tend to go is a better predictor of our happiness than the activities in which we are engaged."
-
Why is this? How can there be a massive glut of unemployed, desperate-for-work individuals in the same country and the same regions where employers (like us) are equally desperate for talent? I’d argue that the fault is systemic and institutional.
-
programming language cheat sheets
Liked what you read? I am available for hire.
A table-based redesign
I'm a big fan of the data-driven approach, and I love basketball, so one of my favorite sites is Ken Pomeroy's stats site, where he tracks tons of statistics for every team, on offense and defense, and lets you break down exactly which parts of each team (rebounding, turnovers, etc) contribute to their success, and which players (efficiency, no. of possessions used, etc) are the most influential.
The site used to be entirely plain text on a blue background, which worked for me, but Ken redesigned the site this year. Last week he posted on Twitter asking for feedback on the redesign.
 I agreed that it was hard to read and I had some feedback. Here's Ken's initial version:
I agreed that it was hard to read and I had some feedback. Here's Ken's initial version:
 Data presentation legend Edward Tufte always says that your design should be as dense as possible; that is, every single piece of ink should convey some bit of information. The table is a good format, especially when you need to search quickly by team instead of by efficiency, but you can change it to make the information easier to scan.
The first step was to replace the heavy black lines between teams. These convey no information and clutter up the design. The best alternative is so-called zebra-striping, where you shade in every alternate line with a light color. The lines are still there, because there are color differences, but they're much more subtle and don't clutter up the display.
Data presentation legend Edward Tufte always says that your design should be as dense as possible; that is, every single piece of ink should convey some bit of information. The table is a good format, especially when you need to search quickly by team instead of by efficiency, but you can change it to make the information easier to scan.
The first step was to replace the heavy black lines between teams. These convey no information and clutter up the design. The best alternative is so-called zebra-striping, where you shade in every alternate line with a light color. The lines are still there, because there are color differences, but they're much more subtle and don't clutter up the display.
 I also took out the vertical dotted lines. However, the purpose of these was to distinguish between like groups. We've already used color to distinguish between line elements, and instead of doing a checkerboard pattern I decided to use spacing to group like elements together. I moved the small-text rankings close to their associated item and increased the space between some of the columns. I also pushed the table width to the full 960 pixels.
The final step was to make it easier to associate the numbers with the team names. I added a gray bar that highlights the table row you are hovering over with your mouse.
I also took out the vertical dotted lines. However, the purpose of these was to distinguish between like groups. We've already used color to distinguish between line elements, and instead of doing a checkerboard pattern I decided to use spacing to group like elements together. I moved the small-text rankings close to their associated item and increased the space between some of the columns. I also pushed the table width to the full 960 pixels.
The final step was to make it easier to associate the numbers with the team names. I added a gray bar that highlights the table row you are hovering over with your mouse.
 All in all, I think it's much more readable and when I have more time I'll explore some other ideas about how to stretch the data. Check it out here.
All in all, I think it's much more readable and when I have more time I'll explore some other ideas about how to stretch the data. Check it out here.
I agreed that it was hard to read and I had some feedback. Here's Ken's initial version:
Data presentation legend Edward Tufte always says that your design should be as dense as possible; that is, every single piece of ink should convey some bit of information. The table is a good format, especially when you need to search quickly by team instead of by efficiency, but you can change it to make the information easier to scan.
The first step was to replace the heavy black lines between teams. These convey no information and clutter up the design. The best alternative is so-called zebra-striping, where you shade in every alternate line with a light color. The lines are still there, because there are color differences, but they're much more subtle and don't clutter up the display.
I also took out the vertical dotted lines. However, the purpose of these was to distinguish between like groups. We've already used color to distinguish between line elements, and instead of doing a checkerboard pattern I decided to use spacing to group like elements together. I moved the small-text rankings close to their associated item and increased the space between some of the columns. I also pushed the table width to the full 960 pixels.
The final step was to make it easier to associate the numbers with the team names. I added a gray bar that highlights the table row you are hovering over with your mouse.
All in all, I think it's much more readable and when I have more time I'll explore some other ideas about how to stretch the data. Check it out here. Liked what you read? I am available for hire.
links for 2010-11-14
-
detroit is in even worse condition than yo uthink
-
guy writes about getting paid to write college students essays
Liked what you read? I am available for hire.
The ACM ICPC: a supposedly fun thing I’ll never do again
Yesterday I was part of CMC's first ever entry into the ACM ICPC, an international programming competition. Last year solving three problems would have been good enough for 5th place, but this year solving three problems was only good enough for 29th out of 75 or so.
The easiest three problems were easy to pick out and we started work on them. The first problem was, given an expected distribution of T-shirt sizes and a number of participants, write some code to determine how many T-shirts to order. The code for this problem was more or less written in the problem description and I was able to solve it in the first twenty minutes or so.
While I was doing that my teammates were working on a cipher problem - given a codeword, create a simple code alphabet and use it to decrypt a message.
While they were doing that going on I started working on the third problem, which was a map labeling algorithm. It was like a Rand McNally map where if you go off the top of the map you have to go to another page on the map. You were given a 'map' divided up into a series of blocks, and had to number each block, and then for each block label the block's neighbors. I solved this one pretty quickly too, however I forgot to remove a print statement from my code, so it was printing an empty line before the output, which cost two incorrect submissions and 40 penalty minutes.
The cipher problem turned out to be fairly difficult. There was a problem with the program that took about an hour to solve, partly because we kept printing out code that we thought was showing one thing when in fact it was showing something else. Also, we had an array of characters that was supposed to hold all of the letters of the alphabet from A to Z, but in fact was missing W. Once we solved those we submitted the code and got the correct answer on the first submission, but by this point we had an hour and a half left.
I started working on the fifth problem, which I thought was the next easiest. The problem was, given a triangle and a thousand points inside that triangle, split the points into three even groups by finding another point inside the triangle.
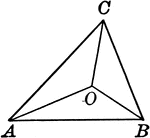 I found the algorithm right away, which was to do a binary search and always move toward the region that contained the most points. However, this turned out to be tricky to implement in practice. Ultimately this problem was really difficult and only a few groups solved it correctly (the winning Harvey Mudd team solved seven of eight problems and this was the one problem they didn't solve). Trying it was a tactical mistake on my part, and we might have been able to solve a fourth if we'd attempted a different problem.
Ultimately it was a long day and as my teammate Jacob noted, "the nerdiest thing I've ever done." It was good I guess, considering I was the only person on our team who'd practiced before the contest and we were the first team ever from CMC to go to the competition. I'd wanted to join the competition because I show my resume to people and they say "Great you're an economics major, so, marketing?" and I wanted to show that I could code a little bit. It would have been great to do better in the competition but them's the breaks.
Among other things this shows how wide the differences between programmers can be; it's estimated that the best programmers are 10 times as efficient as average programmers, and looking at the times to completion it's easy to see how this is true. By the time I solved Problem 1 the Harvey Mudd team had already solved three problems, and there were some teams there that didn't even solve a single problem. These are hard to measure, which is why it's so important to actually look at someone's code to see how they do things, or ask them to write sample code.
All of my practice code can be found here; unfortunately you can't keep the code you wrote during the competition.
I found the algorithm right away, which was to do a binary search and always move toward the region that contained the most points. However, this turned out to be tricky to implement in practice. Ultimately this problem was really difficult and only a few groups solved it correctly (the winning Harvey Mudd team solved seven of eight problems and this was the one problem they didn't solve). Trying it was a tactical mistake on my part, and we might have been able to solve a fourth if we'd attempted a different problem.
Ultimately it was a long day and as my teammate Jacob noted, "the nerdiest thing I've ever done." It was good I guess, considering I was the only person on our team who'd practiced before the contest and we were the first team ever from CMC to go to the competition. I'd wanted to join the competition because I show my resume to people and they say "Great you're an economics major, so, marketing?" and I wanted to show that I could code a little bit. It would have been great to do better in the competition but them's the breaks.
Among other things this shows how wide the differences between programmers can be; it's estimated that the best programmers are 10 times as efficient as average programmers, and looking at the times to completion it's easy to see how this is true. By the time I solved Problem 1 the Harvey Mudd team had already solved three problems, and there were some teams there that didn't even solve a single problem. These are hard to measure, which is why it's so important to actually look at someone's code to see how they do things, or ask them to write sample code.
All of my practice code can be found here; unfortunately you can't keep the code you wrote during the competition.
I found the algorithm right away, which was to do a binary search and always move toward the region that contained the most points. However, this turned out to be tricky to implement in practice. Ultimately this problem was really difficult and only a few groups solved it correctly (the winning Harvey Mudd team solved seven of eight problems and this was the one problem they didn't solve). Trying it was a tactical mistake on my part, and we might have been able to solve a fourth if we'd attempted a different problem.
Ultimately it was a long day and as my teammate Jacob noted, "the nerdiest thing I've ever done." It was good I guess, considering I was the only person on our team who'd practiced before the contest and we were the first team ever from CMC to go to the competition. I'd wanted to join the competition because I show my resume to people and they say "Great you're an economics major, so, marketing?" and I wanted to show that I could code a little bit. It would have been great to do better in the competition but them's the breaks.
Among other things this shows how wide the differences between programmers can be; it's estimated that the best programmers are 10 times as efficient as average programmers, and looking at the times to completion it's easy to see how this is true. By the time I solved Problem 1 the Harvey Mudd team had already solved three problems, and there were some teams there that didn't even solve a single problem. These are hard to measure, which is why it's so important to actually look at someone's code to see how they do things, or ask them to write sample code.
All of my practice code can be found here; unfortunately you can't keep the code you wrote during the competition. Liked what you read? I am available for hire.
Sorry for the repeat posts
It's a problem with the Delicious auto-poster and I cannot turn it off, when I try to load the settings in Delicious.com, I'm told that they are having temporary problems. Apologies for the trouble.
Liked what you read? I am available for hire.
links for 2010-11-13
-
economic principles explained in seinfeld
Liked what you read? I am available for hire.
