Walnut Creek's Design Review Commission is reviewing a new apartment building on Botelho Drive across from the Habit this evening. Like every project proposed in Walnut Creek recently, it cannot be built under the city's normal zoning code, so it is using state density bonus law to waive laws around heights and setbacks that make the project financially unworkable.
Like every other podium apartment proposed recently it feels like a giant missed opportunity. I hope the Design Review Commission - and the city - can spend a bit more time thinking about, and trying to remove, the constraints that make it hard to produce a building that families can live in.
As someone with two young kids it's always been notable, and odd, that Alma Park, up the hill, has no kids facilities - no swing, no playground, no basketball hoop. This would be a great chance to try to fix that. But the proposed building has no three or four bedroom units, and the interior courtyard is going to struggle to get sunlight. The lack of three+ bedroom units means that there are going to continue to be few product types available in Walnut Creek for families. It is hard for a lot of people to afford a $1.5m single family detached house but if that is the only living option available that offers three bedrooms then that will substantially constrain who can live here and hamper young couples ability to have children.
Most of the apartments have a window on just one side. The interior facing rooms on the lower floors are going to have a lot of trouble getting light in. With a window on only one side, you can't ventilate your apartment by opening windows on multiple sides. This increases the demand for HVAC, which increases the cost of living.
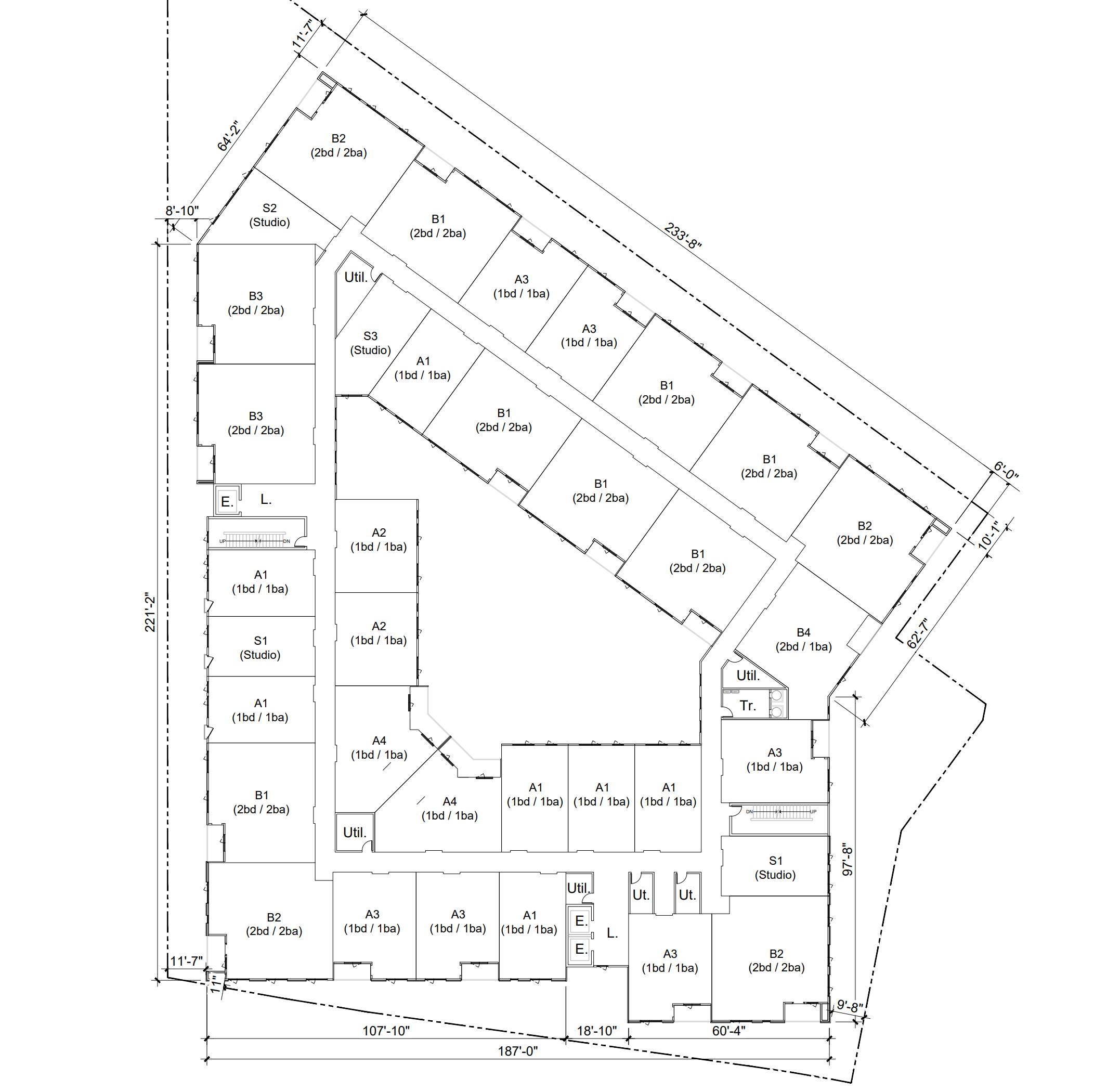
It's possible to do better - a lot better! In other countries, you very rarely see this "double loaded corridor" design. Here's an apartment in Copenhagen, Denmark that is actually denser (149 homes/acre) than this proposal, and the same average height.

Look at this floor plan. Every apartment has windows on multiple sides and at least one balcony, sometimes two.
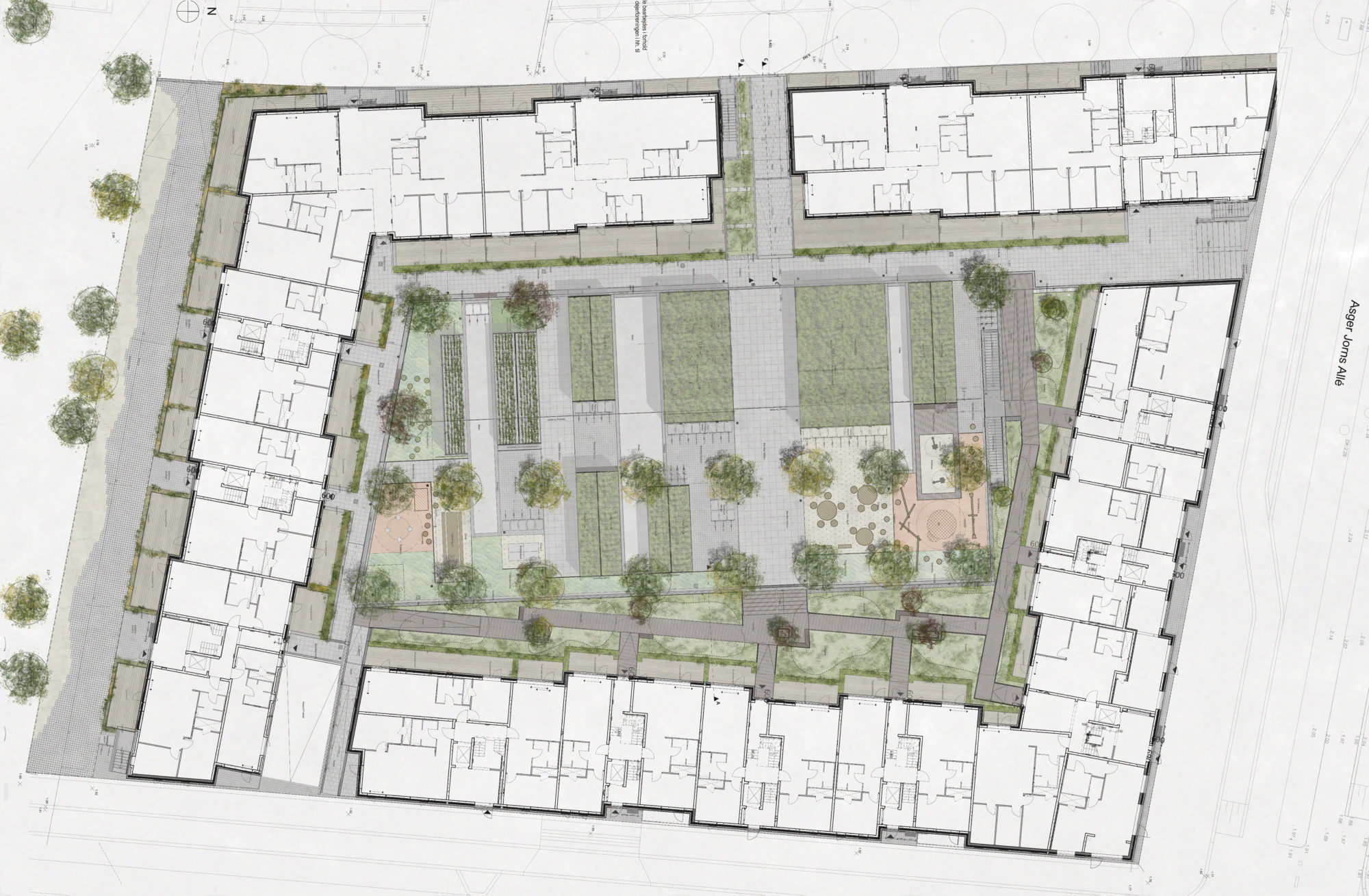
When you have windows on multiple sides it is a lot easier to offer units that have lots of bedrooms. This project has tons of family sized apartments. And when every room is multiple aspect you can do stuff like offer a 900 square foot one bedroom unit.
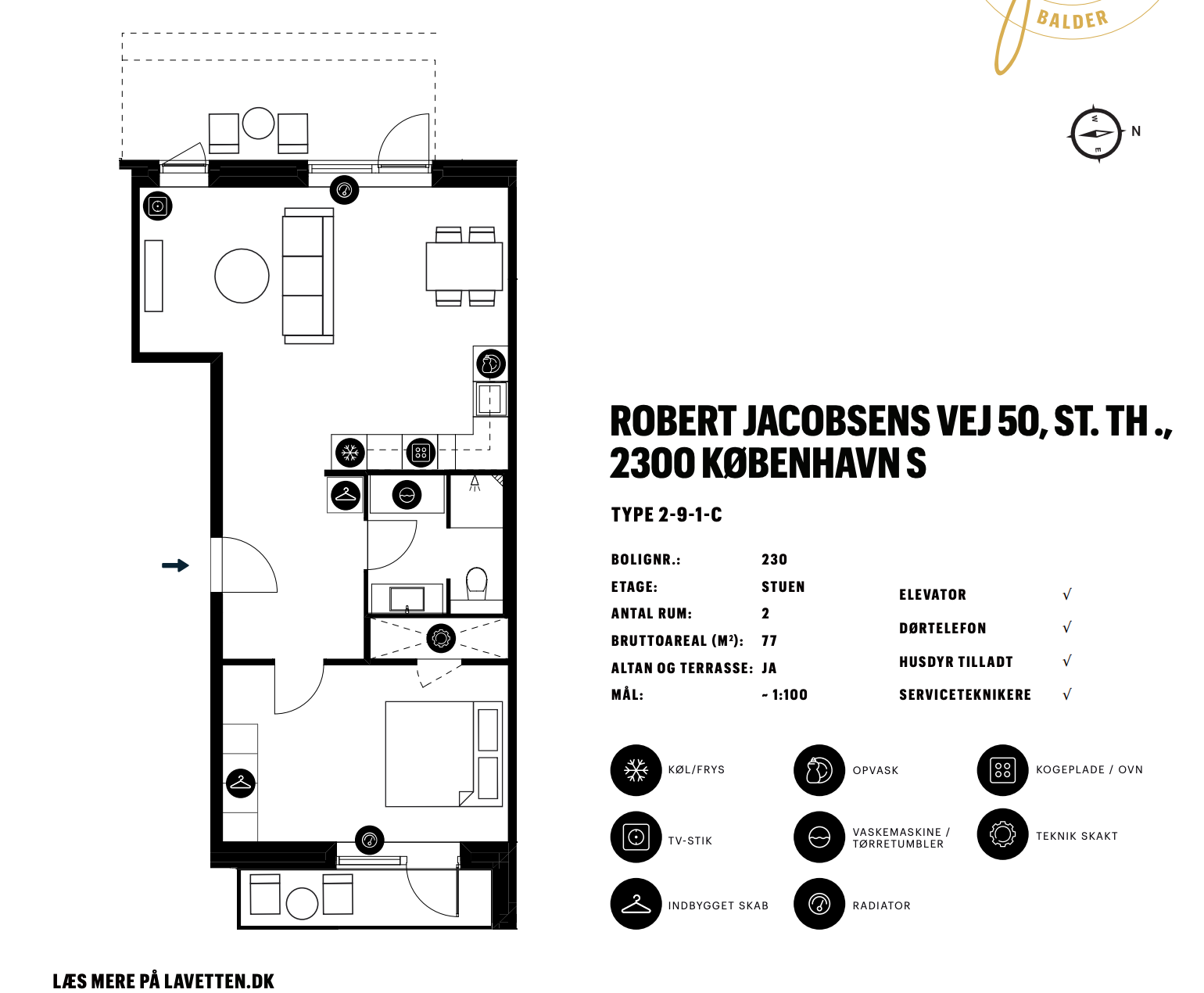
The median household income here in Walnut Creek is $130,000 - more than double the median Copenhagen income - but there are zero 900 square foot one bedroom apartments here that have windows on multiple sides.
And when you don't need to dedicate as much interior space to circulation, you can have a sunlight filled interior courtyard. With a playground. Look how much light there is on this playground! This is a building my family could live in.

I really hope the city can spend some time thinking about why we can't design apartments in Walnut Creek with four bedrooms and sunlight and courtyards that have playgrounds in them. Here are some of the constraints:
-
Minimum parking: The parking requirements shape the whole design of the building but parking is about to radically change forever. In five years it will be possible to buy a car that can drop you off and then go park itself in an offsite garage. The onsite parking in this building has maybe a ten year useful life, in a building with a seventy five year lifespan. If we as a city were willing to be more aggressive about offstreet parking and encouraging other options - we could get much more livable buildings with cheaper rent.
Some neighbors have complained about the building height, and this is also an answer for them. If we could cut the amount of space dedicated to parking we could cut a floor off the building.
-
Parking standards: All of the city's rules about aisle widths and stall widths and lengths assume a human is parking every car. A robot is capable of parking cars with an inch of clearance on both sides. A self driven car cannot block anyone in. "Humans park their own cars" will be true for maybe five more years and for the next seventy years of this building's designed life, the sixteen foot wide drive aisles, and nine foot wide parking stalls will age like sour milk.
Maybe this building in 2026 can't assume robots are parking the cars. But we could change the city's rules now and maybe a building a year from now will be able to dedicate less space to parking.
The global leader in self driving cars has a headquarters thirty miles from here - the city could invite someone from Waymo to give a talk on the future of onsite parking and how our codes should adapt.
-
Stairways: Walnut Creek requires buildings to have two stairway exits from all rooms, which is why there's an interior corridor, why most apartments have only one wall with a window, and why there are no three bedroom apartments - if you have three bedrooms facing a window you have too much unwindowed space in the interior. While sprinklers do a lot to help prevent fires, the evidence for the safety usefulness of the second staircase is mixed at best. Some of the apartments in this building are hundreds of feet from both staircases. Cities and states around the country are changing their rules to permit taller buildings with a single, fire-hardened stair and a balcony. Culver City (pop. 45000) legalized single stair construction up to six stories last year. We could ask their staff to give a talk on what they did.
It's also worth considering the second order effect - when new buildings are so expensive this means more people are still living in older wood buildings that have lead paint and no sprinkler system at all.
-
Heights: The Copenhagen project dips down in the southern corner to let light into the courtyard. This project has an ideal southern exposure to do something similar, but when you are getting 80-85% usable floor space, paying $150k a unit in fees, and elevators cost $500,000, you can't afford luxuries like that.
-
Elevators: The US elevator code is different than the standard used in every other country in the world, so we cannot buy the same cheap elevators as everyone else. We also require every new elevator to be big enough to hold a 7 foot stretcher, because a fire marshal in Glendale, Arizona wanted to make sure that the elevators in the Arizona Cardinals football stadium could fit a stretcher. This means new buildings have fewer elevators, and they're more expensive, and they take up more floor space. The extra cost - both installation and maintenance - gets passed through as higher rent.
The city could hold a study session to learn more about this problem, or meet with / write a letter to our legislators asking for reform.
I understand that these are hard problems. But it would be really helpful for a city commission to at least acknowledge that they exist, acknowledge that the poor quality of multifamily housing is a product of building and zoning regulations, and understand that other countries are able to produce affordable family sized apartments with far more sunlight and passive cooling, and start discussing the constraints that make those impossible to build here.
And if you want to live in a family sized apartment - send this post to your local commission or elected official, and ask them to pursue the changes that would make this possible.
I do not know how much time Rebecca Bauer-Kahan and Tim Grayson have spent this year thinking about the elevator code. But if a local city was writing them letters or getting stories in the local paper then maybe there could be more movement toward getting beautiful, dense, livable new buildings in Walnut Creek. (And a playground for Alma Park).
Comments can be sent to PublicComments@walnut-creek.org.
Liked what you read? I am available for hire.