*This post originally appeared on Shyp's engineering blog in July 2015. It has since been deleted. It is reproduced as closely as possible here. The original is accessible on the Wayback Machine.
Eight months ago when I ran our core API tests at Shyp, it took 100 seconds from starting the test to seeing output on the screen. Today it takes about 100 milliseconds:
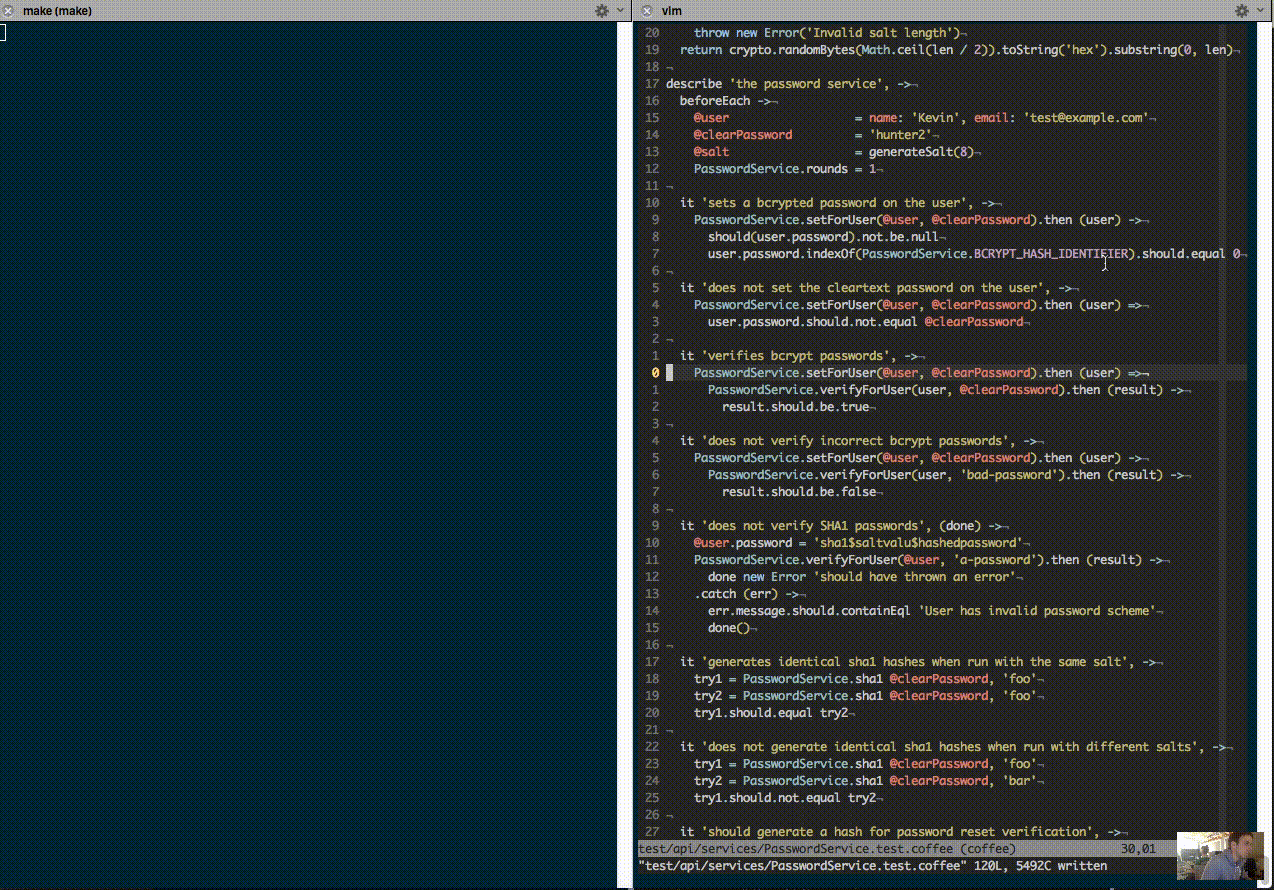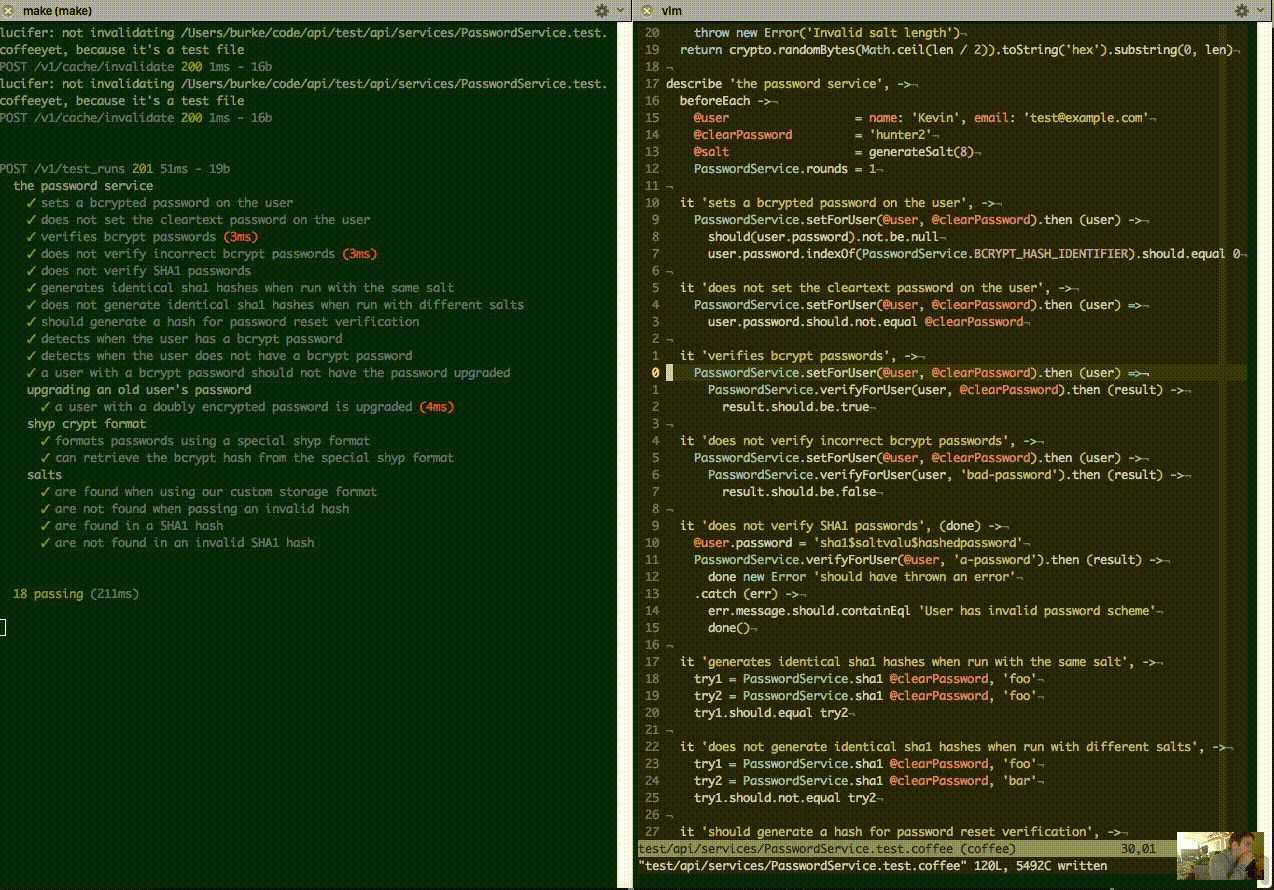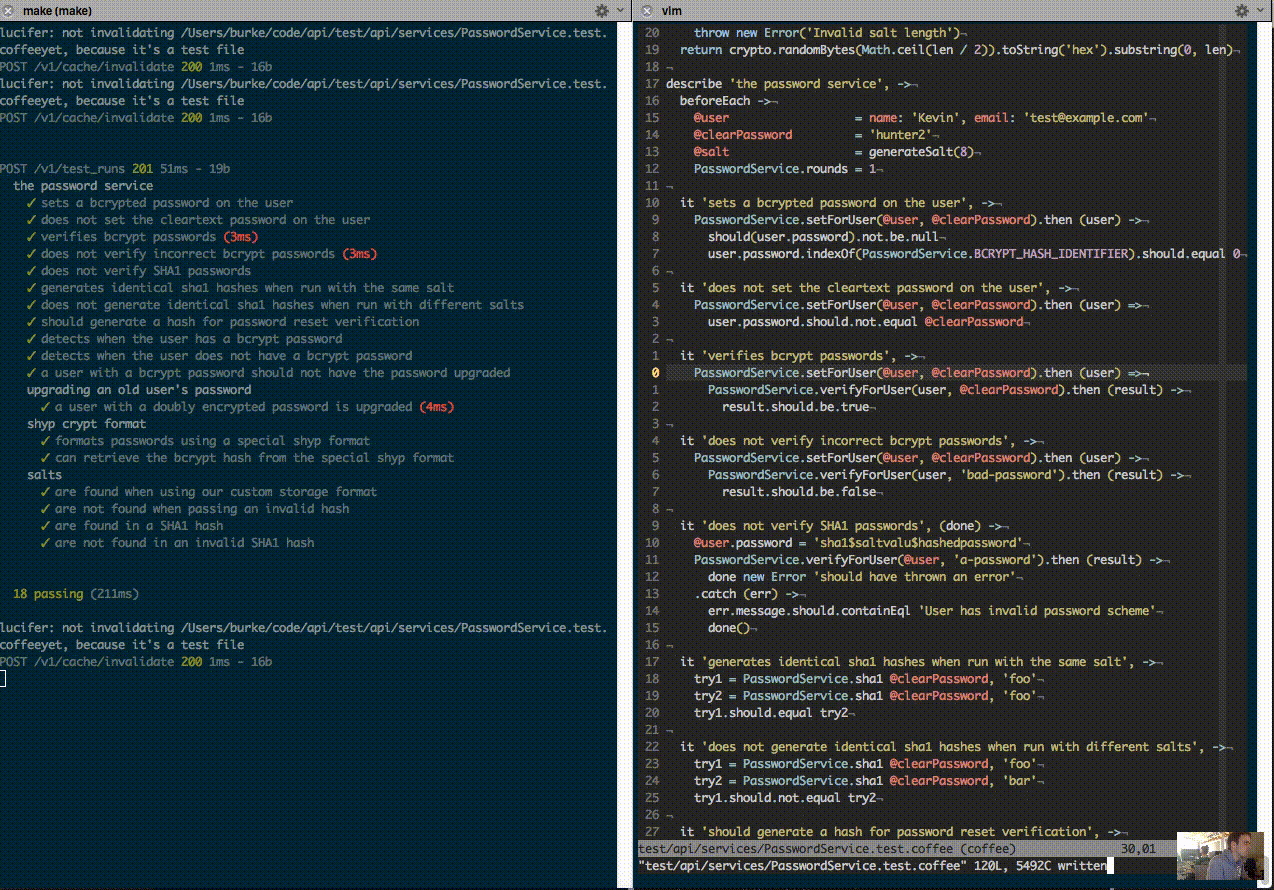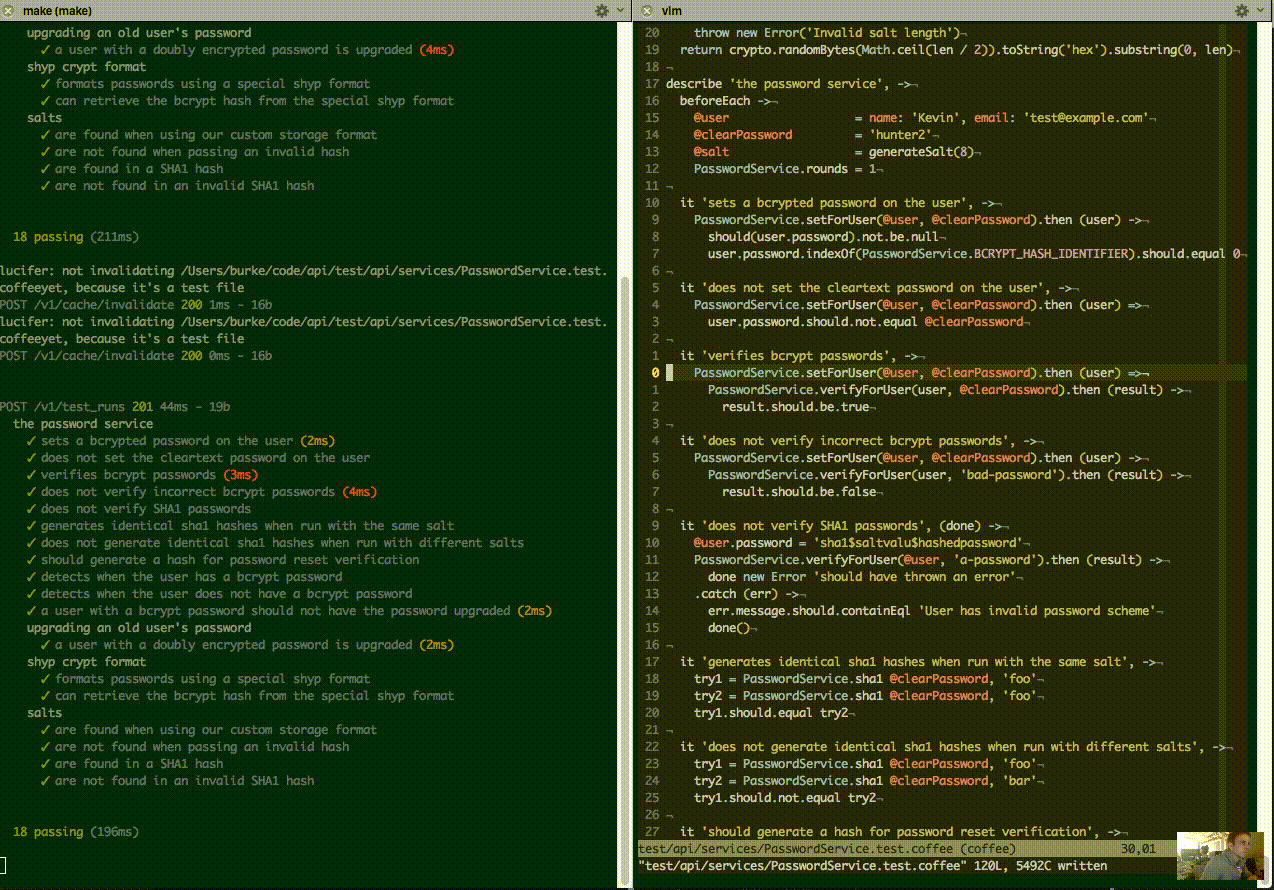
Why Bother?
There are a lot of different demands on your time, why is a speedy test framework so important? Here are a few reasons we put a premium on being able to run tests quickly.
-
Deployments get faster. Our build/deployment server runs every test before a deployment. Making our tests faster means that we spend less time between pushing code and seeing it live in production. In situations where production is broken and we need to push a fix, faster tests mean we can get that fix to production more quickly.
-
Gains accrue over time. We run tests 400-500 times a day; a ten second improvement in every test run translates to an hour of saved developer time, every day.
-
Slow tests lead to context switches. Context switches are harmful. Distractions are everywhere with Slack, push notifications and open-plan offices. A ten or twenty second delay between kicking off a test run and viewing the results means you might be tempted to check email or Twitter or do any other activity which causes you to lose focus on the task at hand. Faster tests mean you can stay focused more easily.
Our target is to get feedback within 100ms; that’s about as much time as a UI can take before it stops feeling responsive and your mind starts to wander.
-
Fast tests lead to better code. We are subconsciously biased against things that are slow. Amazon famously found that 100ms of latency costs 1% of sales. You might want to refactor a module, but subconsciously decide not to, because refactoring implies running the tests, and the tests are slow. You might not write an extra test you really should write, because it means running the test suite again, and the tests are slow. You might decide not to be curious about a test anomaly, because narrowing down the issue would require running the tests, and the tests are slow.
For these reasons, it’s important to us that we start to see test output in under 100ms. Fortunately, we were able to hit that goal. How did we do it?
Measuring Performance
The first step to making anything faster is to measure how fast or slow it is. At a minimum, you’ll want to measure:
-
How long it takes before the first test starts running
-
How long it takes to perform any global, per-test setup/teardown actions
-
Minimum amount of time to do a database read (for us, 4ms)
-
How long each test takes. If you run your tests with mocha, I encourage you to set the --slow flag to 2 (milliseconds) so you can clearly see how long each test takes to run.
There’s an awesome Unix tool called ts (available on Macs via brew install moreutils) that will annotate every line of your test output with a timestamp. Pipe your test output through ts like so:
mocha test/api/responses/notFound.test.js | ts '[%Y-%m-%d %H:%M:%.S]'
And you’ll get test output annotated with timestamps with millisecond precision; all you need to do is find the right place to put console.log lines.
[2015-04-19 21:53:45.730679] verbose: request hook loaded successfully.
[2015-04-19 21:53:45.731032] verbose: Loading the app's models and adapters...
[2015-04-19 21:53:45.731095] verbose: Loading app models...
[2015-04-19 21:53:47.928104] verbose: Loading app adapters...
[2015-04-19 21:53:47.929343] verbose: Loading blueprint middleware...
We observed right away that a) our Node framework requires a ton of files before starting a test run, b) require is synchronous, and really slow in Node (on the order of milliseconds per file imported), and c) There were a ton of stat() syscalls to try and load modules in places where those modules did not exist.
The latter problem is documented in more detail on my personal blog, and there have been two promising developments in that area. First, Gleb Bahmutov developed the cache-require-paths library, which helps Node remember where it found a file the last time it was imported, and avoids many wasteful/incorrect file seeks. Gleb observed a 36-38% speedup when loading an Express project - our speedup was closer to 20%, but we are still really glad this tool exists.
Second, Pierre Ingelbert submitted a patch to io.js to avoid extraneous stat() syscalls in directories that do not exist. This patch was part of the io.js 2.3.1 release.
Loading Shared Folders Kills Performance
We run our tests in a virtual machine, so our development environment matches production. The core api project is shared between the host machine (usually a Mac) and the VM. Loading the test suite means that a lot of files in the node_modules directory are being loaded. If that node_modules folder lives inside the folder that’s being shared, the VM will have to reach across the system boundary to read it, which is much slower than reading a file inside the virtual machine.
It was clear we needed to install our node_modules folder somewhere inside the VM, but outside of the shared folder. Node’s NODE_PATH environment variable provides a mechanism for loading a folder saved elsewhere on the filesystem, but our Javascript framework hard-codes the location of the node_modules folder in its imports, so it failed to find the files we had placed elsewhere.
Instead we installed the node_modules folder elsewhere and symlinked it into place. Here’s a bash snippet you can use to replicate this behavior.
pushd ~/api
npm install --prefix /opt/lib/node_modules
ln -s /opt/lib/node_modules ~/api/node_modules
popd
Savings: This sped up test initialization time by a whopping 75%, or one minute and fifteen seconds.
More Specific Regex
We used to specify a test to run by typing mocha -g 'testname' at the command line. Unfortunately, mocha always loads a mocha.opts file if it is present, and our mocha.opts file hard coded a filename regex that matched every single test file in our system (100+ files). We added a new test runner and instructed people to manually specify the test file they want to run.
Savings: This sped up test run time by about 50% (10-13 seconds).
Stubbed database reads/writes
The old test framework would do authentication by writing a valid access token to the database, then reading/returning the valid access token in the controller. We introduced a synchronous signIn test helper that stubbed these two network calls.
Savings: 10-20ms across ~600 tests, a 6-12 second improvement.
Batched writes
In some instances we need to instantiate test environments with users, drivers and other objects. Previously the test helper would write one record, read the id, and then write a record that depended on it. By generating ids up front, we were able to perform multiple writes at the same time.
Savings: 10-20ms across ~200 tests, a 2-4 second improvement.
Faster test cleanup
Between each test, we delete all records from the database. The helper responsible for this would open one database connection per table and then each one would call DELETE FROM <tablename>. Not only would this occasionally hang with no stack trace, it meant that the speed of the cleanup operation was the same as the slowest DELETE query.
Instead we grouped all of the deletes and sent them to the database in a single connection (e.g. Model.query("DELETE FROM users; DELETE FROM pickups; ...")). Some reading online indicated TRUNCATE would be faster than DELETE; plus, it lets you use one command for everything, e.g. TRUNCATE TABLE users, pickups, .... For large datasets it is likely faster, however we observed this to be much slower than DELETE for our small test data sets, on the order of 200ms per action.
An optimization we’d like to implement in the future would only issue DELETEs for tables that have dirty data, which would also let us avoid issuing a DELETE if a test didn’t hit the database. Currently we’re not sure about the best way to hook into the ORM and determine this.
We’re also interested in running every test in a transaction. Unfortunately the ORM we use doesn’t support transactions, and we are very worried about upgrading it.
Savings: Clearing the DB used to take 14-30ms per test, now takes 3-11ms, a ~20 second improvement.
Don’t Load Sails
Our Javascript framework (Sails.js) needs to require every single model, controller, and service before it runs; this is the slowest part of the test run by far.
Where possible, we try to avoid loading Sails when writing/running tests. We try to implement most of our business logic in plain Javascript classes or modules, outside of models and controllers. If this logic operates on objects in memory, you can use fake model objects in your tests - var user = {email: 'foo@bar.com'}, and avoid loading Sails entirely.
Avoiding Sails isn’t possible in every situation, but we’ve found it’s a useful design principle - it helps us separate our business logic and our data storage layer, and will make it easier for us to move off Sails in the future.
For more on this technique, you should check out Gary Bernhardt’s excellent Destroy All Software series of videos. He gave a great introduction to his “don’t load Rails” style of testing at Pycon in 2012 (summary here).
Tighter Editor Integration
Most of the time the test you want to run is the same one that is right underneath your cursor, so manually specifying the filename at the command line wastes time. The awesome vim-test plugin makes it incredibly easy to map leader commands for running the current suite of tests or the current file. It worked on literally the first try; I’ve rarely been so impressed with a piece of software.
Some of our team members use Sublime Text, and we haven’t figured out how to get their editor integration set up yet. It’s on our to do list for this quarter.
Savings: One context switch and ~1-3 seconds per test run.
Avoid Reloading All Dependencies Every Test Run
After all of this we were able to get test run time down to about 7 seconds. Most of this time is spent waiting for v8 to parse/require ~500 files.
We can go much faster if we loaded every dependency once when we sat down at the computer, and then only re-required the files that had changed. You can do this by hacking with Node’s require.cache. I don’t recommend it for production, but it works just fine.
Anyway the end result of this is a command line client and a server called Lucifer. Start Lucifer when you sit down at your computer. When we change a file, we call lucifer invalidate [filename] (or configure our editors to do this for us), which invalidates the cache for that file, and then re-requires it. Then you can kick off a test run by calling lucifer run [filename] from the command line (or from your editor). When you kick off a test every dependency is ready to go, which means your tests start in about 100ms.
Savings: Test initialization time went from 6-7 seconds to 100ms, a 60x speedup.
Caveats
This is similar to the approach taken by spork in Ruby - keep a server up and reload changed files. The same failure modes that apply to Spork - increased complexity, subtle inconsistencies, failure to reload files - apply here. In particular, we’ve found that sometimes Node doesn’t wipe the cache for files that have changed, so new code won’t get loaded. This is probably a result of our limited understanding of how and where Node caches loaded dependencies. We always do a clean run of our test suite on our build server before deploying to production.
Still, it’s been very useful in certain situations - if you’ve flushed out a method or a controller and are writing several tests in quick succession, the only file that’s changing is your test file, so the chance of subtle dependency breakage is low.
Lessons
Your slow test suite isn’t hopeless! But improving it is probably going to take a concerted investment. You also have to get know your stack really well, which is probably a good idea anyway. Look at all of the places we had to inspect to find performance improvements:
- File reads in a virtual machine
- The
require function in Node
- Test workflow
- Use batching to avoid database connection overhead
- Editor integration
You don’t know what will be slow until you measure it. You’ll also want to know how to use basic profiling tools for your stack:
- the ts command
- Strace/DTruss (not covered in depth here, but extremely useful for observing system calls/timings for a running process)
- Logging / timing for queries that hit the database
- Logging and profiling your test run time
We’re hiring!
Our team of ten engineers powers four warehouses, four mobile apps, hundreds of drivers and loads of pickups every day. We’re looking for people who are curious about the tools they use and eager to improve their productivity day in and day out. We’d love to hear from you; you can’t waste our time by getting in touch.
Errata
Some odd things I found while profiling:
Liked what you read? I am available for hire.